
Forrás: 2017. szeptember 25. -
A GDPR kapcsán számos esetben felmerült az a kérdés, hogy ha nem tudjuk meghatározni valahogy, mely adatok tartoznak a hatóköre alá – azaz, mely fájlok tartalmaznak személyes adatokat – akkor hogyan követjük nyomon ezeket az adatokat, illetve hogyan tudunk védelmi intézkedéseket biztosítani ezekkel az állományokkal kapcsolatban.
Nyilván nem csak a GDP szempontjából fontos, hogy valamilyen módon besoroljuk az a százhetvenmillió fájlt, amelyek a fájlszervereinken és a felhasználók munkaállomásain találhatók: bármilyen adatszivárgásvédelmi megoldás bevezetéséhez is erre van szükség, tehát az adatklasszifikáció kiemelt fontosságú ezekben a projektekben.
Az adatklasszifikáció ugye nem más, mint az adat valamely szempontok szerinti osztályba sorolása, annak érdekében, hogy az adott adatosztályra megfelelő védelmi (és természetesen tárolási és felhasználási) intézkedések legyenek hozhatók.
És akkor már ott is tartunk az adatvagyon leltár misztikus témakörénél...
A DLP gyártók előszeretettel hangsúlyozzák, hogy az ő rendszerükben van eDiscovery/Discovery/Crawler/stb. modul, amely automatikusan végigmegy a megadott tárterületeken (és adatbázisokban) és a felprogramozásának megfelelően megtalálja és feltárja a szenzitív adatokat, és amelyeket akkor már meg is fog tudni védeni.
Ez a kijelentés igaz, de fenntartásokkal kezelendő.
Automatikus adatklasszifikáció
Az automatikus adatklasszifikáció során az adatfelismerő/feltáró modul valamilyen adatfelismerésen alapulva találja meg az érzékeny adatokat és jelöli meg a DLP számára, mint védendő információt.
Adatfelismerési lehetőségek:
- Kulcsszavas felismerés (ha az adott adatban/fájlban szerepel az „alma” ÉS/VAGY a „körte” LEGALÁBB háromszor, a szabály illeszkedik és az adat megfelel a kulcsszavas szabálynak)
- Reguláris (regexp) felismerés (pl. durva IP cím felismerő kifejezés: \b\d{1,3}\.\d{1,3}\.\d{1,3}\.\d{1,3}\b – de ez illeszkedik az 1.1.1.1-re is)
- Reguláris felismerés, algoritmusos validációval (az előző példából kiindulva, az illeszkedés pontatlan, de egy algoritmussal validálható, hogy a regexp-el felismert string valóban IP cím-e, például bankkártya-szám esetében Luhn-algoritmus a validátor),
- Gépi tanulás (ismertessük meg a rendszerrel, hogy néz ki egy árajánlat, aztán ismertessük meg a rendszerrel, hogy néz ki ami nem árajánlat, és akkor a rendszer képes lesz felismerni az árajánlatot)
- Indexelés és digitális lenyomatolás (a felismerendő adatról hash lenyomatok képződnek, és a rendszer innentől részleges egyezéseket és képes lesz majd észlelni, csak ugye előbb meg kell mondani a rendszernek, milyen fájlokat és adatokat indexeljen vagy lenyomatoljon!!)
- Illetve ezek kombinációja.
Nagytömegű adatmennyiség esetén kézenfekvő módszernek tűnik az automatikus klasszifikáció, hiszen felprogramozzuk a rendszert, elengedjük, és már meg is van az adatklasszifikáció, a DLP rendszer már tudja is milyen adatokat kell megvédeni.
Az első probléma ezzel kapcsolatban az, hogy a felismerések meglehetősen pontatlanok, illetőleg a rendszer betanítása se nem egyszerű, se nem gyors. Ráadásul, valakinek meg kell tanítania a rendszert, de ki lesz az, aki az összes szenzitív információt felméri a szervezeten belül, majd leképezi az adatfelismerő rendszer számára?
A második probléma az automatikus rendszerrel kapcsolatban, hogy naponta irdatlan tömegű új állomány és adat képződik egy nagy szervezeten belül, amelyek nem feltétlenül fognak egyezni a már felprogramozott adatfelismerésekkel, viszont arra nincs lehetőség, hogy az adatfelismerő komponens folyamatosan tunningolásra, finomításra, bővítésre kerüljön. Ennek az lesz az eredménye, hogy lesznek olyan adatok, amelyeket a rendszer nem lesz képes felismerni és emiatt majd megvédeni.
A harmadik probléma az adatklasszifikációval a reklasszifikációs folyamat maga: azaz a rendszernek periodikusan újra és újra ellenőriznie kell az adott fájlokat, tartalmaznak-e még olyan szenzitív adatokat, amelyekre valamely adatfelismerő szabály egyezik. Ez tehát egy soha véget nem érő történet, egy kedves barátom nemrégiben fejezett be egy nagyvállalatnál egy adatklasszifikációs projektet, amely csaknem 1 évig tartott, és most kezdheti előröl: 1 év alatt annyi új adat keletkezett és annyira megváltozott az adatstruktúra, hogy reklasszifikálni kell az adatvagyonleltárt.
A negyedik probléma műszaki jellegű: az adatok és fájlok feltárása nagy terhelést tesz a fájlszerverekre, el lehet képzelni, hogy amikor egy discovery fut, minden egyes fájlt a rendszer átrángat magához, szétszedi, kinyeri belőle és megpróbálja felismerni az adattartalmat. A hálózatosok rémálma különben, még akkor is, ha a jobb rendszerekben lehet paraméterezni a sebességet és a feldolgozást. (És akkor még nem is beszéltünk az irdatlan tömegű, képi formátumú adatról: szkennelt PDF és JPG állományok, amelyekhez már a rendszernek OCR komponenssel is kell rendelkeznie.)
Manuális adatklasszifikáció
Nem kell megijedni, nem arról van szó, hogy a CISO-nak kézzel, minden egyes fájlt be kell sorolnia, nem.
A manuális klasszifikáció lényege, hogy az egyes fájlok besorolását nem egy automata rendszer végzi, hanem az a személy, aki a legjobban ismeri annak a fájlnak a tartalmát – az a személy, aki létrehozta vagy dolgozik vele.
A felhasználó.
Ezek az önálló klasszifikációs (labeling, tagging) rendszerek beépülnek a felhasználók Office alkalmazásaiba és a Windowsba és segítségével a felhasználó az általa létrehozott, megnyitott, módosított dokumentumokat és akár emaileket.
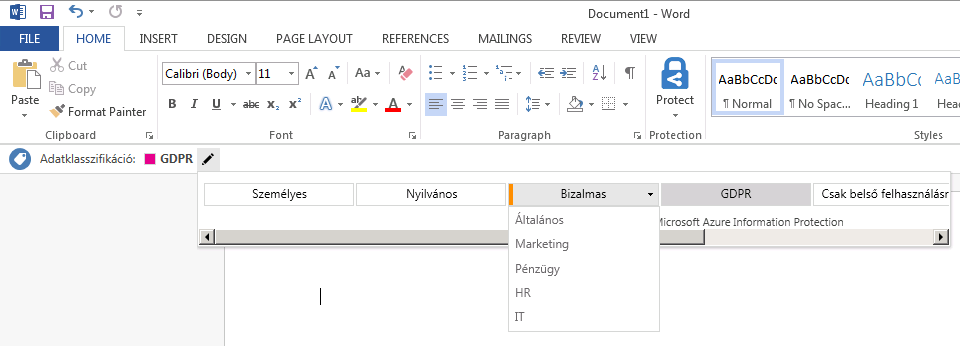
Microsoft Azure Information Protection (Word komponens, címke és alcímke kategóriák)
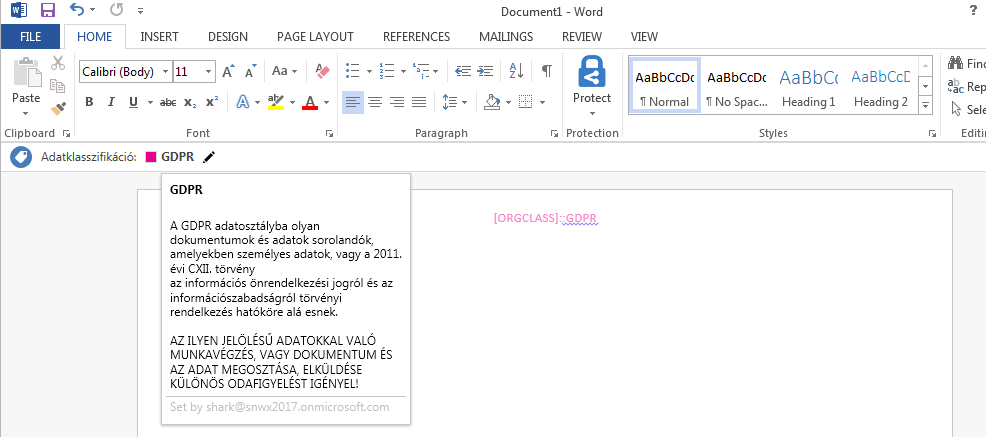
Microsoft Azure Information Protection (Word komponens, GDPR-ra címkézve)
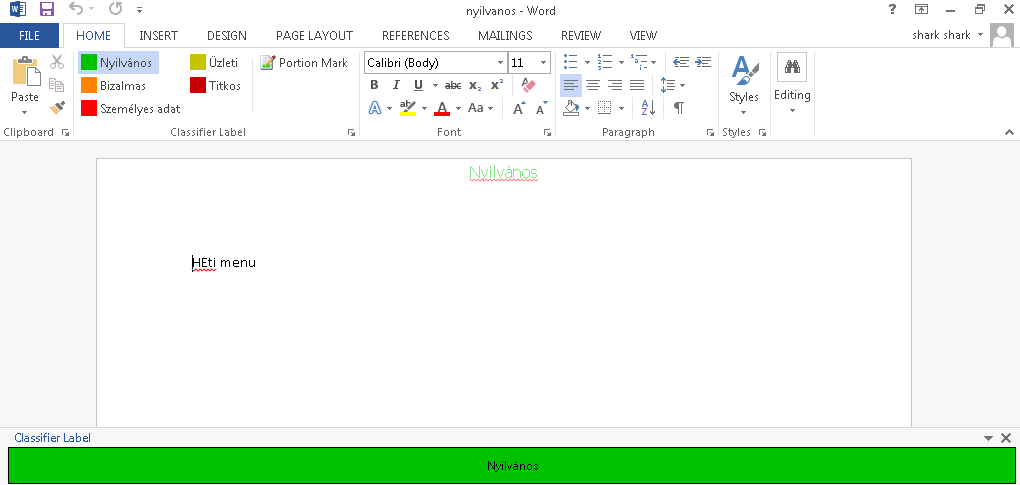
Boldon James Classifier (Word komponens, "Nyilvános" minősítés
Természetesen a tagging/labeling rendszerek csak fájlokkal tudnak dolgozni, adatbázisokban nincs lehetőség címkéket elhelyezni (az automata, DLP discovery rendszerek többsége képes adatbázisokból is tanulni, illetve onnan származó adatokat felismerni).
A labeling rendszereknek az előnye, hogy (elvileg) sokkal pontosabb klasszifikációt eredményeznek: maga a felhasználó - aki az adott állománnyal dolgozik – sorolja be az adatot valamely adatosztályba. A reklasszifikáció is sokkal gyorsabb és pontosabb, ha a dokumentum már nem tartalmaz szenzitív információkat, a felhasználó egyszerűen átteszi egy másik adatosztályba a dokumentumot.
Az ilyen tagging/labeling rendszerek beépülhetnek Exchange szerverbe, Officeba, Outlookba, OWA-ba, SharePointba, és persze az Explorer-be – nyilván attól függően, hogy melyik gyártóval kerül a szervezet kapcsolatba.
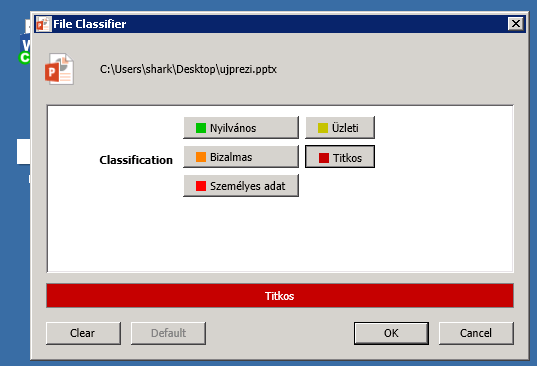
Boldon James Classifier (Explorer komponens)
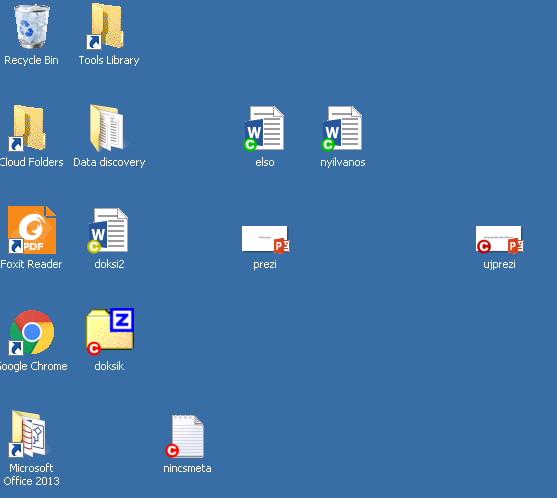
Boldon James Classifier (Explorer komponens, ikonvizualizáció)
A labeling/tagging rendszerek összekapcsolhatók a jobb DLP megoldásokkal (nem véletlenül, a labeling vendorok és a DLP vendorok szoros barátságot ápolnak), képesek felismerni a fájlokra tett címkéket, és ezek alapján védelmi intézkedéseket foganatosítani.
A címkéző rendszerek többnyire a fájlok metaadataiba helyezik el a jelöléseket, gyártótól függően azonban van lehetőség az alternate data stream (ADS) használatára is: az olyan rendszerek, amelyek támogatják az ADS-t, bármilyen fájlt képesek megtaggelni, míg a csak metaadattal dolgozók csak olyan fájlokat tudnak megjelölni, amelyeknek van hozzáférhető metaadat blokkja – praktikusan az Office és PDF dokumentumokra korlátozódnak.
A DLP és content filter eszközök képesek tehát észlelni ezeket a címkéket, és egyszerű szabályokkal kontrolálni az ilyen fájlok mozgását (pl: az Internal Only címkéjű fájlok nem hagyhatják el a szervezetet, míg a GDRP jelölésű fájlok email vagy web továbbítása naplózásra és vizsgálatra kerül.).
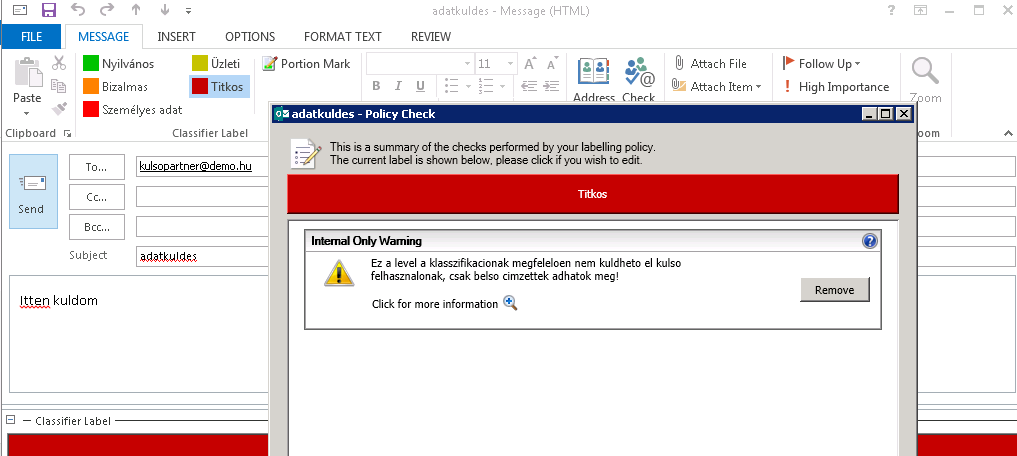
Boldon James Classifier (Outlook komponens, "Titkos" minősítésű levél/csatolmány küldésének blokkolása)
A legtöbb labeling rendszer rendelkezik valamilyen CLI-alapú komponenssel (vagy saját alkalmazás, vagy PowerShell), amely összekapcsolható a DLP rendszerekkel és automatikus adatklasszifikáló rendszerekkel.
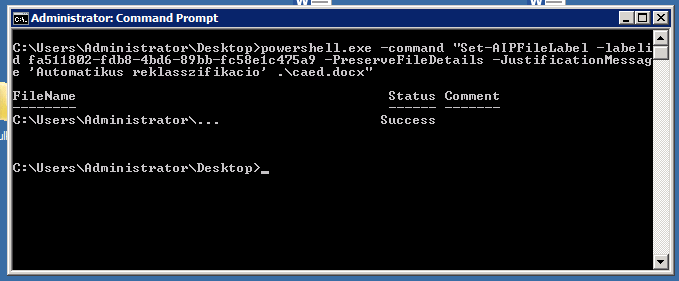
Microsoft Azure Information Protection (PowerShell klasszifikáció)
Ilyen integráció esetén ha a DLP rendszer Discovery komponense valamely felprogramozott rutin alapján felismer szenzitív adatot egy dokumentumban, képes meghívni a labeling rendszer CLI-interfészét, amely a megfelelő címkével fogja ellátni az adott dokumentumot.
Ez az integráció a reklasszifikációt teszi manuálissá: a DLP rendszer automatikus modulja által felismert (vélt vagy valós szenzitív adat) adatot a címkéző rendszer automatikusan megtaggeli, de ha a felhasználó nem ért egyet a besorolással, a dokumentumot szerkesztés/módosítás közben átsorolhatja másik adatosztályba (amelyre a DLP rendszer más védelmi szabályt fog már foganatosítani).
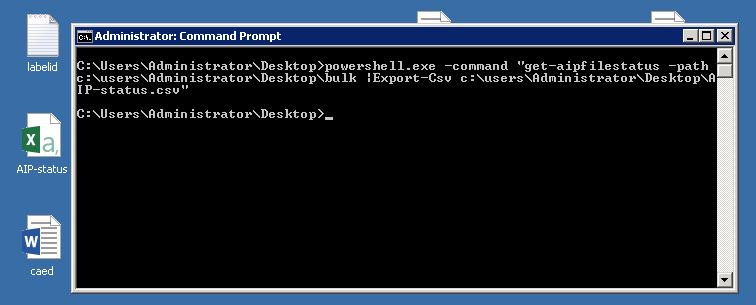
Microsoft Azure Information Protection (PowerShell komponens, adatleltár készítése mappából)
Látható, hogy a labeling rendszerek nem védelmi megoldások, nem arra készültek, hogy megvédjék az adott fájlt (bár vannak gyártók, akik még védelmi funkciókat is biztosítanak), de a védelmi rendszerek keze alá dolgozva növelik a védelmi rendszerek hatékonyságát és csökkentik a pontatlan felismerésekből származó false-positive arányt.
A legnagyobb értéke azonban (szerintem) a labeling rendszereknek az, hogy NEM az IT biztonsági vagy üzemeltetési területnek kell az adatosztályozással foglalkoznia, az adatokat besorolnia vagy reklasszifikálnia: ezt a feladat (és felelősség!) átterhelhető arra a személyre aki a legpontosabban meg tudja mondani, mit tartalmaz az adott fájl: a fájlal dolgozó felhasználóra.

